



パーソナライゼーションにおけるディープラーニング

目次
概要
Yuspパーソナライゼーションエンジンは、様々な業種にてパーソナライゼーションのソリューションとなる多種多様なレコメンデーションアルゴリズムを展開しています。Yuspの最近のアルゴリズム開発では、セッションベースのレコメンデーション課題を解決すべく、ディープラーニングレコメンデーションの枠組みを構築しています。
このケースでは、ユーザーのセッション中の行動(ブラウジングや検索など)に基づいて関連性の高いレコメンデーションを提供し、そのユーザーに次に表示する商品やコンテンツを予測することが目標です。これは多くの導入例における典型的なセットアップでありながら、専門家や研究コミュニティからの注目は大きくはありませんでした。
ユーザーの真の目的をブラウジングセッション中にリアルタイムで汲み取り、これに基づいて関連性の高いコンテンツを表示すれば、オンラインユーザー体験は大幅に向上します。
このアルゴリズムはYusp(Gravity R&D)のリサーチチームによる開発成果であり、Yuspパーソナライゼーションエンジンへの実装の最適化も達成されました。このフレームワークは様々なパーソナライゼーション事例にてテストされ、異なるビジネスKPI(詳しくは事例をご参照ください)におけるA/Bテストにて他の代表的なメソッドと比べ大幅な優位性(5~15%)が実証されました。
更なる利点としては、GDPRなどの規制にデフォルトで対応していることです。これは、セッションベースということで、本セットアップはセッション外まで顧客データを保持する必要が無いからです。
本稿では、ディープラーニングとは何か、そしてどのようにパーソナライゼーションに活用するかをご紹介します。その後、弊社の事例をいくつかご紹介し、ディープラーニングを用いた他のパーソナライゼーション関連アプリケーションをご紹介します。パーソナライゼーションにおけるディープラーニングの長所と短所を簡潔に整理した後に、弊社チームが今後研究開発を進めていく方向性にも軽く触れていきます。
ディープラーニングとは?
ディープラーニングはマシンラーニングの中の1つの分野で、大量の非線形処理レイヤー(別称「深層ニューラルネットワーク」)を用いてデータのあらゆる表現を学習するものです。
ディープラーニングは2010年代初期から今まで画像認識、音声認識、自然言語処理などの複雑な分野へのアプローチにおいて劇的な成長を見せてきました。
ディープラーニングのレコメンデーション業界への取り入れは2015年後半に、小数の先進的なリサーチグループによって始まりました。Yuspの元会社であるGravity R&D社はこの先駆者達の一つとして、この分野のリーダーの1人とされています。
セッションベースのレコメンデーションがパーソナライゼーションエンジンに欠かせない理由は?
セッションベースのレコメンデーションはマシンラーニングおよびパーソナライゼーション業界において長らく放置されてきたテーマですが、重要なケースがいくつも存在します。
セッションを跨ぐユーザートラッキングはそこまで重要ではありません。
cookieやブラウザフィンガープリントなど、ユーザー識別技術は多くの場合、特に異なるデバイスやプラットフォーム間では信頼性に欠けます。この技術はcookieトラッキングを無効にしているユーザーを認識することができない他、許可したユーザーにとってプライバシー関連の壁となる可能性もあります。
多くのEコマース及びコンテンツサイトは、cookieの保存期限の影響もあり、サイトの閲覧頻度が低い消費者のトラッキングは行いません。また、ユーザートラッキングが可能であっても、トラック用cookieの有効期限内で実行したセッションはたったの1~2件かもしれません。そこで、特定ドメイン(クラシファイドサイトなど)において、ユーザーの行動はセッションベースの特性を可視化します。
ユーザートラッキングが正常に稼働している場合でも、ユーザーの目的を常にリアルタイムでパーソナライズドレコメンデーションに活用するべきです。しかしこれはセッション毎に異なる場合も大いにあります。そういったケースのためのアルゴリズムを構築するに向け、1人のユーザーが複数のセッションを開いた場合、それぞれを独立したものとして扱うべきです。
これをセッションベースレコメンデーション問題と称します。
これまで、パーソナライゼーションエンジンにおけるこの問題の一般的な解決方法は、ユーザーの最後のクリックをトラックし、同セッション内のその他のクリックは除外する、というシンプルなものでした。
パーソナライゼーションにおけるディープラーニングの初期
我々がセッションベースレコメンデーションの研究を始める以前は、パーソナライゼーション関連のタスクを処理できるディープラーニングアプリケーションは数えるほどしかありませんでした。
似た方法に、制限ボルツマンマシン(RBM)を用いた協調フィルタリングというものがありました。RBMでは、2層のニューラルネットワークを用いて、ユーザー・アイテムインタラクションのモデリングや、レコメンデーションの提供が行われます。これはNetflix Prizeの問題に応用され、最も優れた協調フィルタリングモデルの1つとなりました。
ディープモデルもまた、非構造化データ(音楽や画像など)から要素を抽出し、より伝統的な協調フィルタリングモデルと合わせて活用するために使われていました。例えば、楽曲ファイルから畳み込みニューラルネットワークを用いて抽出した要素を、ファクターモデルに使用する、といった流れです。より汎用的なアプローチでは、ディープネットワークはあらゆる種類のアイテムから、汎用的なコンテンツ・要素を抽出する際に使用されます。そしてこれらの情報はスタンダートな協調フィルタリングモデルへと集約され、レコメンデーションの性能を向上させます。
他のマシンラーニング分野においては、様々なディープモデルが効果的に導入されました。導入エリアは画像・楽曲・音声認識から、自然言語処理、機械翻訳、バイオインフォマティクス、医薬品設計など、多岐にわたります。
Yusp研究チームの功績
我々がセッションベースのレコメンデーション用に選択したディープニューラルネットワークモデルは、再帰型ニューラルネットワーク(RNN)です。RNNはシーケンス処理における代表的なディープラーニングソリューションで、テキスト翻訳から自動画像注釈まで、様々な事例において効果を発揮しています。
ただ、RNNのコンセプトをレコメンデーション環境へと適応させる必要があります。Yuspチームは初めに、ゲート付き回帰型ユニット(GRU)を用いた、より発達したRNNのバージョンを探しました。そしてYuspチームは、レコメンデーションドメイン用のGRUベースのRNNモデルに下記の変更を行いました:
- セッション並行のミニバッチ
- ミニバッチベースのカスタム負例サンプリング
- レコメンドアイテムの順位付け用のカスタム損失関数
こうして「GRU4Rec」と名付けられたこのアルゴリズムは、セッションベースのレコメンデーションに向けて設計されています。例えば、ユーザーの実行中のセッションを継続させるために効果的なアイテムをレコメンドする、などです。
また、セッションベースの行動があまり普及していないエリアでは、ドメインの実際のセッションの代わりに、最近のユーザー履歴を参照することも可能です。GRU4Recについての詳細は、弊社のICLR 2016(pdf)やCIKM 2018(pdf)などの資料をご覧ください。
研究用の実装もgithubにて公開しました。商用ライセンス付きもございます。
ケーススタディ
2017年より、YuspチームはGravity R&Dによって最適化されたGRU4RecをYuspパーソナライゼーションエンジンに統合しました。このソリューションは実社会の様々なレコメンデーション環境において、他の優秀なメソッドとA/Bテストで比較したところ、評価の大幅な上昇(5~15%)が見られました。
ビデオポータル
1つ目のケーススタディでは、YouTubeに似たOTT動画サイトにおけるパーソナライゼーション事例をご紹介します。ユーザーの興味がセッション毎に頻繁に変わるため、セッションベースレコメンデーションの用例には度々用いられる事例です。
例えば、ユーザーが長期的な履歴からして全く異なる種類の動画をクリックした場合には、様々な動機・ファクターが推測されます。ユーザーはしばしば、ソーシャルネットワーク、ウェブサイトやメッセージングアプリに埋め込まれたリンクなど、外部ページを経由して動画サイトに辿り着きます。ユーザーがcookieをブロックしている場合は特に、ブラウザがパスを辿れないため、同一ユーザーによる2度の閲覧はおろか、同一ソーシャルネットワークからのアクセスも紐づけすることができていません。
多くのケースでは、最後の閲覧から一定期間が経過してcookieの有効期限が切れたユーザーが、初回アクセスとして処理されます。この初回アクセスはビデオポータルにとって、ユーザーの興味・嗜好を掴み、よりアクセス頻度の高いユーザーへとコンバートする機会となります。
YuspのディープラーニングモジュールとGRU4Recの性能を測るため、Yuspチームは閲覧者を4つのランダムグループに分類し、比較研究を実施しました。各グループ内の閲覧者は、選択されたアルゴリズムによって生成されたレコメンドを受信しました。Yuspチームは2.5ヶ月にわたり、4つのアルゴリズムをテストしました:
- ベースラインアルゴリズム:OTTサイトの全リクエストをYuspが処理してきたもの
- RNN:GRU4Recの初期バージョン(CIKM 2018資料にて解説)
- RNN seq:前項と同じモデルを用いて、n個の別々のベストな予測ではなく、n個の動画のシーケンスをレコメンド
- CF方式:2つのRNNバージョンと同じデータで調整された、アイテム間の協調フィルタリングアルゴリズム
アルゴリズムの初めてのプロダクションテストでした。よって、レコメンデーションボックス内でRNNとRNN seqがそれぞれのユーザーグループに向けてレコメンドを表示する枠は限られていました。ボックス内の残りの枠は、ベースラインアルゴリズムが埋めました。こうして、グループ間の差異を軽減しました。
この実験では下記の指標を精査しました。OTT動画業界では、クリック・再生・視聴数と表示できる広告の数及び広告収益は比例するので、これらの評価基準は収益に直接影響します。
- 視聴時間/Rec:ユーザーの動画視聴時間(秒)÷レコメンド数
- 再生/Rec:PLAYEDイベント数÷レコメンド数
- 視聴/Rec:VIEWイベント数÷レコメンド数
- クリック/Rec:レコメンドのクリック数÷レコメンド数(CTRに近い指標)
Yuspチームは各ユーザーグループの全指標を計算しました。PLAYEDイベントとVIEWイベントの違いは、PLAYEDではユーザーが動画の一定割合を視聴する必要があるのに対し、VIEWではそのような条件が含まれない、という点です。よって、PLAYEDイベントのほうがVIEWイベントよりも高いユーザー嗜好を示すと考えています。
結果を以下のグラフに示しました。RNN、RNN seq、CFのアルゴリズムのパフォーマンスを、100%と設定したYuspベースラインアルゴリズム(グループB)と比較しています。
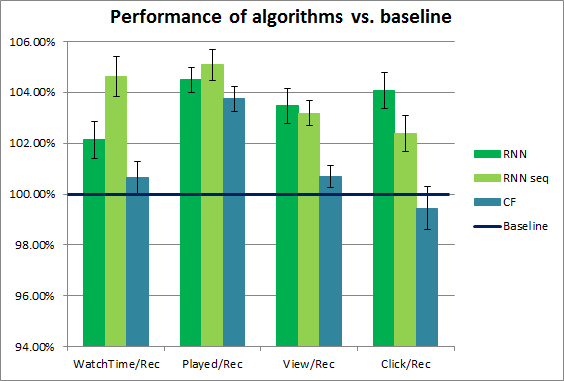
結果をまとめると:
- 限られた枠でも、RNNとRNN seqの両者は全ての指標においてベースアルゴリズムを大幅に上回った
- RNNとRNN seqはベースラインよりも、レコメンドリクエスト1000件につき、それぞれ779秒と1674秒多かった
- PLAYEDイベントの件数もまた、レコメンドリクエスト1000件につき26.9と31.3の増加
- VIEWイベントの件数も、レコメンドリクエスト1000件につき52.5と47の増加
- CFに対する優位性は少し減るものの、顕著に表れた
- RNNとRNN seqはCFよりも、レコメンドリクエスト1000件につき、371秒と1266秒多かった
- PLAYEDイベント数はレコメンドリクエスト1000件につき5.5と9.8の増加
- VIEWイベント数はレコメンドリクエスト1000件につき32.8と38.4の増加
- CFはプリフィルタリングデータで学習したため、ベースロジックよりも優れていた
- RNN seqは従来のRNNと比べ、視聴時間とPLAYEDイベント/Recにおいて大幅に優れていた
- シーケンス予測は従来のRNNと比べ、レコメンドリクエスト1000件につき8950秒の増加
- PLAYEDイベント数もレコメンドリクエスト1000件につき4.4の増加
- VIEWイベント数に大きな差は無かった
- クリック数はレコメンドリクエスト1000件につき3.2の減少
結論として、今回の調査対象の指標においては最大5%の増加が見られたと言えます。広告収益が表示ボリュームに比例すると仮定した場合、この5%の増加はそのまま動画サイトでの広告収益の増加率とも解釈できます。
市場
セッションベース戦略が消費者の行動モデルを効果的に構築する場として、「レコメンデーションシナリオ」または「プレースメント」というものがあります。OTTサイト同様に、購入する商品を探す消費者の興味はセッション毎に変わる場合があります。
2つの典型的なプレースメントは以下の通りです:
- 商品ページ:ハイライトされた商品に類似した、ユーザーの興味を惹きそうな商品のレコメンド
- メインページ:ユーザーの過去のクリックに基づいた、パーソナライズドレコメンデーション
各ユーザーに対して最も好感触な商品を予測する商品ページプレースメントにおいては、セッションベースレコメンデーションロジックの導入は複雑ではありません。表示中のページ上のハイライトされた商品のみではなく、当該ユーザーが最後に閲覧した数件のアイテムも参照しながらレコメンドが生成されます。
次にご紹介するように、セッションベース戦略ではメインページプレースメントにおいてもKPIの増加が見込めます。メインページがセッションの入口となった場合、GRU4Recアルゴリズムはユーザーの前回のセッションデータを参照するため、ユーザーがセッションに復帰した際にはセッション内データを用いります。
フォールバックとして、両方のプレースメントにおいて、GRU4Recがデータ欠如を原因に必要数の商品を予測できなかった場合に、Yuspチームはベースラインレコメンデーションロジックを使用しました。フォールバック率は商品ページでは約10~15%、メインページでは約25~30%となりました。後者の原因として挙がっているのは、初回閲覧者や低頻度(cookieの無い)ユーザーの存在です。
10ヶ月間の長期的な研究では、YuspのディープラーニングモジュールとGRU4Recを、RNNベースのディープラーニングアルゴリズムと同じ学習を済ませた高性能かつパーソナライズされた協調フィルタリングベースラインアルゴリズムと比較しました。
この実験では、新たなレコメンデーション戦略がもたらす収益、そして収益増加率を測ることで、GRU4Recアルゴリズムのビジネスへの直接的影響を分析することができます。主なRAW指標として、Yuspチームは両方のプレースメントにおけるレコメンデーション関連の収益を計測しました。以下のグラフにて、日毎の収益増加率の総合的な統計を示しています(信頼区間:p=0.05)。
グラフにおけるアイテムページとメインページのテスト結果から、それぞれ最初の30日間と60日間は除外しました。この初期の期間では、総合統計は大きな変動や広い信頼区間を持つからです。1つ目のグラフに見られる落下も、同様の効果であると考えます。
収益の変動を示す際に、プライバシー保護の観点から正確な数値は共有しかねますが、マーケットプレイスサイトにおける高いビジネス価値は示せたでしょう。
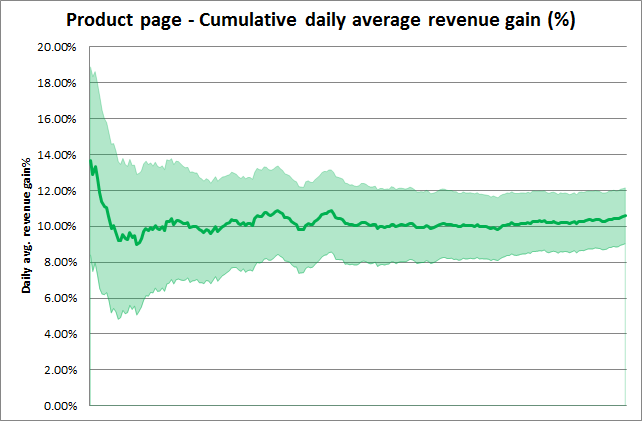
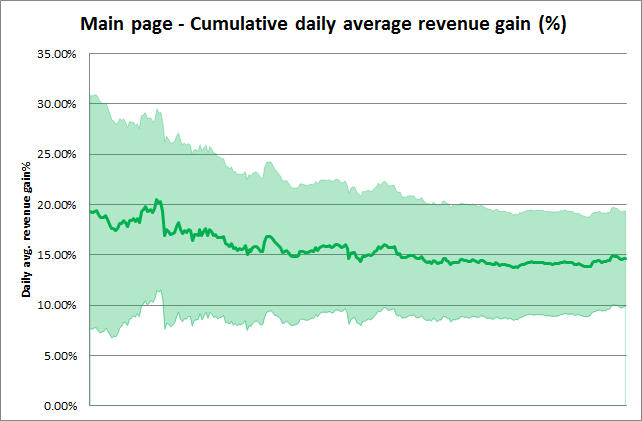
これらのグラフでは、緑色の濃い線は累積的な収益増加率を、緑色の薄いエリアは収益増加率の累積信頼度(p=0.05)を示します。
結果として、対象の2つのプレースメントにおいて、セッションベースレコメンデーションは収益を大幅に増加させたと言えます。収益増加の日毎平均は:
- メインページでは14.6%
- 商品ページでは10.6%
となりました。
長期的な実験の副作用として、ベースラインの協調フィルタリングアルゴリズムもまたGRU4Recの効果的なレコメンデーションから学習することで、度合いの正確な計測は不可能ですが、システムの総合的なパフォーマンスも向上しています。
結果をまとめると、GRU4Recのセッションベースアルゴリズムを用いたマーケットプレイスサイトの2種類のプレースメントでのレコメンデーションでは、およそ15%の収益増加が確認できました。
パーソナライゼーション業界におけるディープラーニングのその他事例
レコメンデーションエンジン分野において、ディープラーニングの導入事例は増加し続けています。こちらでは、目を引くものや、特徴のある事例をご紹介します。
ディスプレイ広告のCTR予測
ディスプレイ広告はオンライン広告の一種で、別ウェブサイトに広告元の広告を掲載するものです。オンライン広告業界では、各社が正確に広告をターゲティングし、ユーザーがクリックする確率が最も高いような広告を表示する必要があります。
このタスクはCTR予測と呼ばれ、表示された広告に対するクリック数と閲覧数の比率を予測するものです。広告のCTRを正確に予測することは、オンライン広告全体の当事者がディスプレイ広告に費やすコストの最適化に直結します。数十億ドルもの市場価値を持つディスプレイ広告において、CTR予測は必要不可欠なタスクです。
CTR予測はマシンラーニング問題としても議論されます。例えば、ユーザー(と広告)の属性が学習要素となり、アウトプットは広告に対するクリック数の予測になります。
CTR予測とプレゼンテーションについては無数のラーニングモデルが提案されてきました。ロジスティック回帰や分解器のような従来型の浅いモデルを超えるべく、近年ではディープモデルも提唱されています。
強力な表現可能性を持つディープモデルは浅いモデルの表現力を上回ることができますが、その代償として解読が複雑になり、システムスペック面での要求も強くなります。このようなアルゴリズムとしてはDeepFM、FiBiNet、Wide&Deep、Deep&Crossなどが挙がります。また、研究者向けの近年のディープモデルのほぼ全てを含む、無料でアクセス可能なgithubレポジトリもございます。
音楽レコメンデーション
ディープラーニングが初めてレコメンドシステムに導入されたのは、音楽業界でした。Sander Dielemanとその仲間たちはこのテーマの先駆者です(NIPS 2013レポート参照)。彼らは協調フィルタリングベースの音楽レコメンデーションに、コールドスタート問題という高い壁を見つけました。新しい楽曲や有名ではない楽曲はレコメンドされず、よって興味を持つ可能性のあるユーザーとの接点も途絶えてしまい、ユーザーを親しい曲だけのフィルターバブルに閉じ込めてしまいます。
音楽業界のコールドスタート問題を克服すべく、ユーザーデータが不足している場合には畳み込みニューラルネットワークを用いて音響信号を処理しました。この処理を従来の潜在変数モデルの箇所に置き換え、反応に優れたレコメンデーションを実現しました。
この仕組みは大手音楽ストリーミングプラットフォーム、Spotifyのレコメンドシステムに導入されました。ニューラルネットワークレイヤーは、ボーカルやコーラス、バスドラムなどの音楽的要素のフィルタグループを構築しています。下記はレイヤーの視覚的表現(出典:Dataconomy)で、Dielemanによると「負の値は赤、正の値は青、ゼロは白です。各フィルタは4フレームの幅しかありません。各フィルタは赤の濃い縦線によって仕切られています。」

また、この表現方法におけるフィルタに基づいてプレイリストを作成することもでき、似た楽曲をまとめることも可能です。注意点を挙げるとすると、これらのフィルタに名前を付けるのは機械ではなく、人間の仕事です。
こちらは環境音楽フィルタのサンプルプレイリストです。このプロジェクトの興味深い特徴の1つとしては、ディープニューラルネットワークが楽曲を讃美歌、中国ポップス、ディープハウスなどのサブジャンルに分類することができる、という点が挙がります。しかしより重要なのは、賢いプレイリストを作り続け、ユーザーが存在すら知り得なかった、曖昧で人気も無い、けれども関連性の高い楽曲と出会う環境が構築されている、ということです。
ディープラーニングの全体像
ディープラーニングモデルはシステム要求が高く、最大限の効果を発揮するにはしばしば特殊なハードウェアも用意する必要があります(CPUではなくGPU、など)。そこで我々の生成システム、Yuspパーソナライゼーションエンジンにとって重要になるのが、計算資源を極力効率的に扱うことです。
Gravity R&Dのチームは常にYuspのディープラーニングモジュールの最適化に取り組んでおり、確実な成果を出しています。これらの成果はYuspのディープラーニング技術の収益性を増加させるためには欠かせないものです。我々のクライアントは、技術を費用便益分析に基づいて評価する、というのも理由の1つです。効果的な導入が成功した場合、弊社エンジンはROIにおいて最低でも10~15倍の結果を出します。これまで行ってきた全ての最適化において、レコメンド精度を犠牲にしたことは決してありません。
製品化に向けて、我々はTensorFlow、pytorch、Theanoなどのディープラーニングフレームワークを分析しました。近年では最初の2つが人気ですが、我々は以下の理由からTheanoを選択しました:
- 長い間、Theanoは唯一の生産レベルでのディープラーニングフレームワークであり、協力しやすいPython APIと導入の簡単さで決まりました。
- 期間中、弊社チームはTheanoの仕組み、Theanoのコードの最適化案、そして拡張性をまとめました。学習プロセスの様々な部分をスピードアップするため、カスタムオペレータをいくつか開発しました。また、弊社の成果もTheanoコミュニティにシェアしました。
- Theanoのオペレータは基本的にGPU向けに最適化されています。学習プロセスは他のフレームワークと比べ、実行前に計算グラフ全体をモノリシックC++/CUDAコードへのコンパイルするため、1つのGPUでも3.5~4倍高速です。1つのGPUの限界性能まで発揮することで、複数のGPUに処理を割り振るよりも、弊社の費用効果に対する信念と合致しました。
以下の最適化も実施しました:
- 賢い前処理レイヤーを携え、GRU4Recはレスポンスタイムが低いCPUでもレコメンドを提供でき、GPUは学習段階でのみ必要になります。大幅なコストカットと同時に、スループットでは33%の増加が見られました。
- 学習時間の大幅な短縮。データの読み込みと前処理プロセスを最適化したことで、学習時間を効率化しました。
- サービス向上。予測サービスの記憶効率を最適化したことで、より大きなカタログサイズを持つクライアントにも対応できるようになりました。
- 「GRU4RecCS」と呼ばれる、ディープラーニングを含む新たなコールドスタートアルゴリズム。このバージョンではコールドスタート(名前最後の「CS」の由来)においても商品のメタデータに基づいて、似た商品をレコメンドすることができます。ソリューションは、①Theanoが効率的に疎行列を処理するためにはカスタムオペレータを実装する必要があります。GPUにおいてNVIDIAと競合している、CUDAで実装しました。ディープラーニングフレームワークにおける一般的なGPUはカスタムオペレータより数段遅く、②モデル学習用に最適なメタデータキャッシュを構築、③オンラインサービス。
結果として、Yuspのディープラーニングモジュールはパフォーマンスとビジネスメリットにおいて確実な成果を遂げています。GRU4Rec系の様々なアルゴリズムを用いて、最低でもハードウェアコストの約10~15倍のROIを実現可能です。
出典: https://www.yusp.com/blog-posts/deep-learning-in-personalization/